ASD Prediction Model
machine learning prediction model
experience info
TYPE
project
YEAR
2025
Contents
- dataset tuning
- data visualization
- supervised learning
- hyperparameter tuning
- model evaluation
description
more than 75,000,000 people worldwide have been diagnosed with autism spectrum disorder (asd), yet accurate diagnosis remains a challenge. a recent study by the journal of the american medical association found that medical teams could correctly diagnose asd in children only 60-89% of the time. given the scale of the condition, this means millions of individuals may be misdiagnosed or remain undiagnosed, leading to delayed interventions and inadequate support. this is where my model comes in—leveraging machine learning to enhance diagnostic accuracy and provide a data-driven approach to autism prediction.
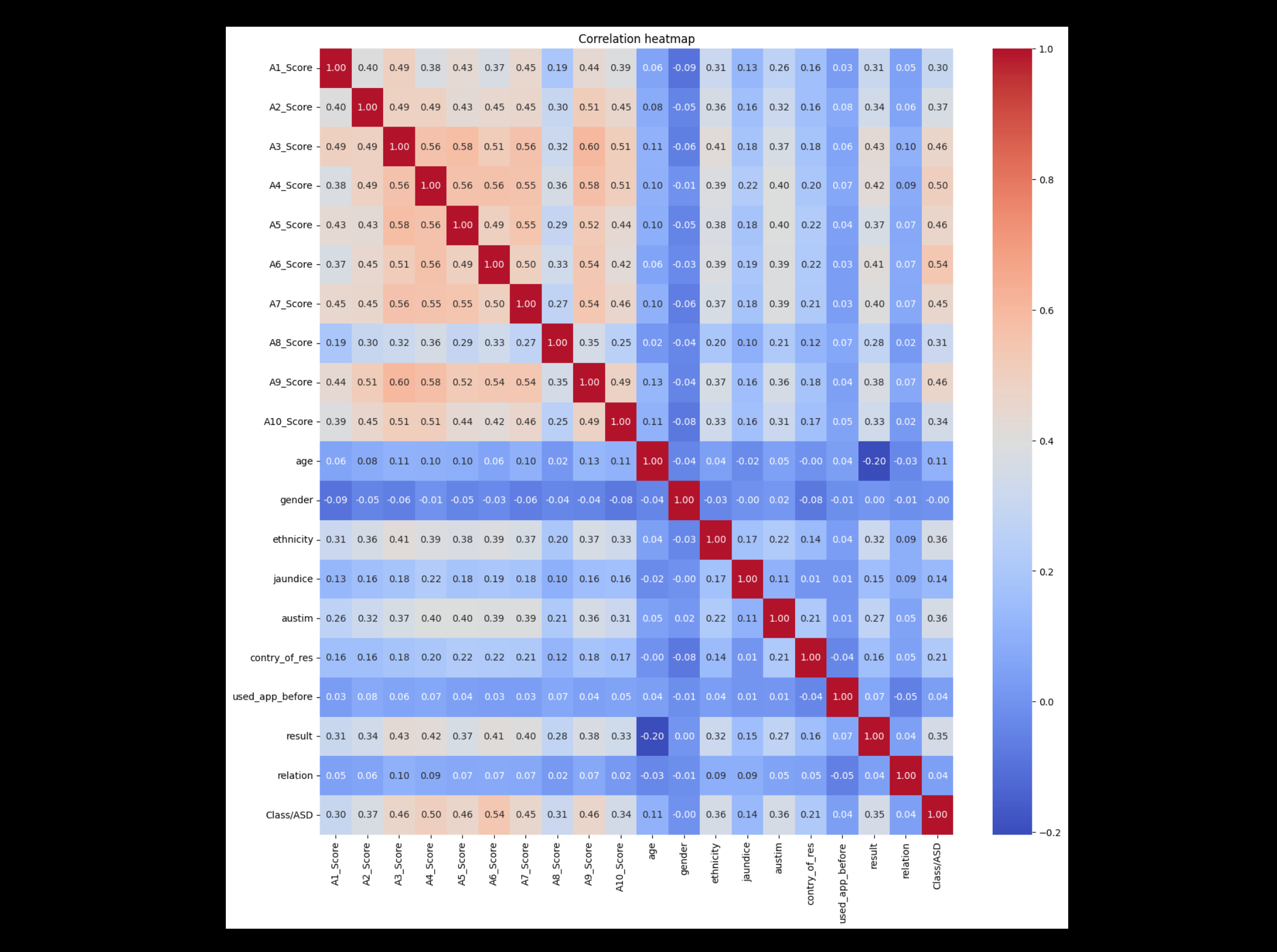
the dataset used for training and testing originates from a kaggle community prediction competition. before building the model, i refined the dataset by removing irrelevant or incomplete columns, ensuring the data was clean, consistent, and optimized for machine learning. data visualization techniques, such as correlation heatmaps, were applied to identify relationships between different features, highlighting the most influential parameters contributing to asd prediction.
this project employs supervised learning algorithms, specifically the decision tree classifier and random forest classifier, to predict the likelihood of asd based on approximately 20 related parameters. decision trees are well-suited for this task as they can capture complex, nonlinear relationships in the data, while random forests, being an ensemble of multiple decision trees, enhance generalization and reduce the risk of overfitting.
to further improve model performance, i conducted hyperparameter tuning using grid search, systematically testing different parameter combinations to optimize accuracy. additionally, smote (synthetic minority over-sampling technique) was applied to address class imbalance, preventing the model from disproportionately favoring the majority class. class imbalance is a critical issue in medical datasets, where cases of a condition are often far fewer than non-cases, leading to biased predictions. smote generates synthetic examples for the minority class, ensuring a more balanced and fair learning process.

to rigorously evaluate the model’s effectiveness, i implemented cross-validation, splitting the dataset into multiple subsets to assess performance across different test scenarios. the final model achieved a 93% cross-validation accuracy, surpassing the reported medical diagnosis accuracy range. this indicates that the model has strong potential for assisting healthcare professionals by offering an additional layer of decision support in asd diagnosis.
by carefully curating the dataset, applying advanced machine learning techniques, and optimizing hyperparameters, this model provides a reliable, efficient, and scalable approach to asd prediction. improving early detection can lead to timely interventions, personalized support, and better long-term outcomes for individuals with autism.